Details on the ReSynth Dataset
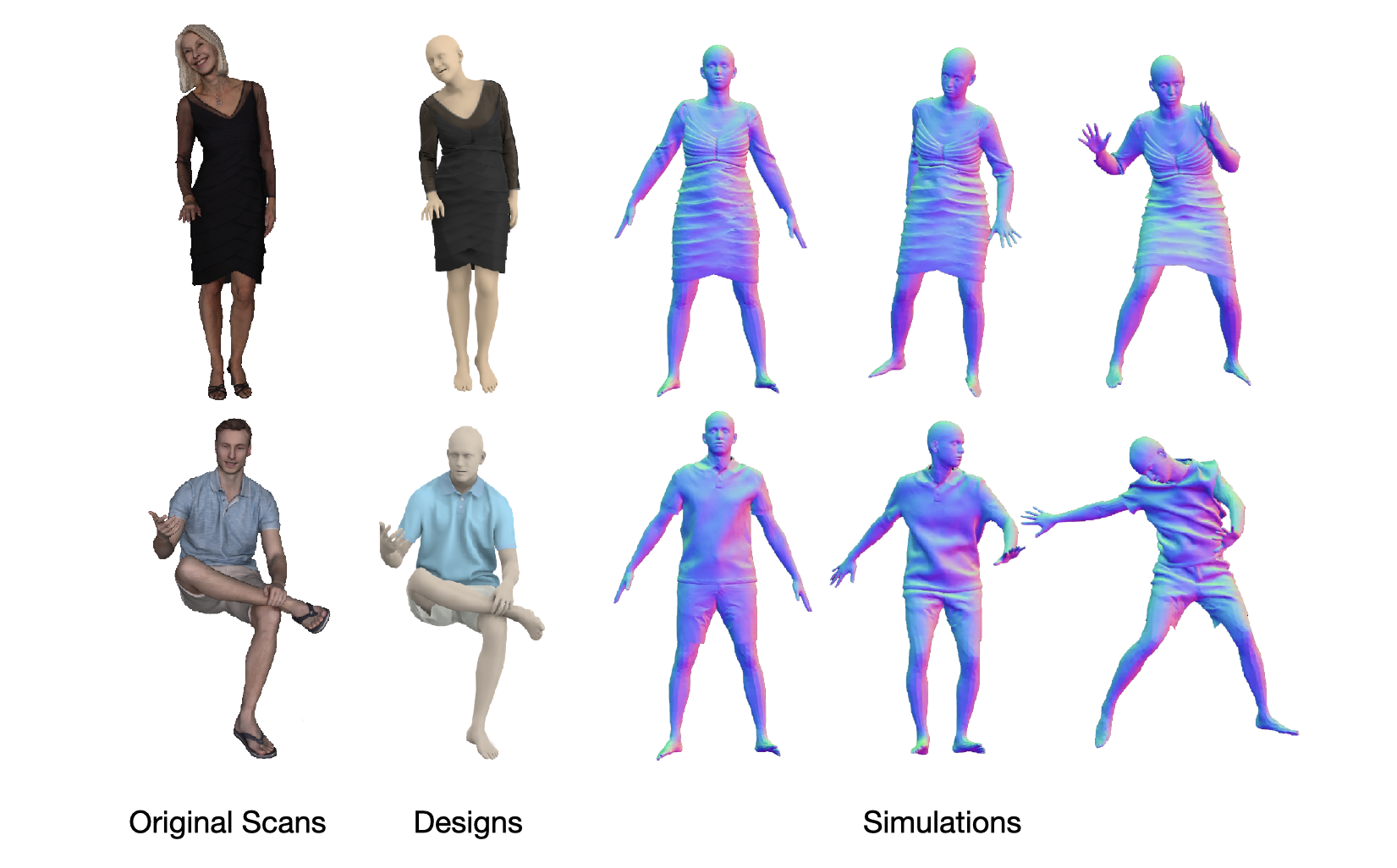
The ReSynth dataset is a synthetic dataset of 3D humans in clothing created using physics-based simulation. The clothing is designed by a professional clothing designer so that they faithfully reflect those in a real scanned dataset of clothed humans (). We provide both the simulated point cloud data and the packed data that are compatible with the / code bases. See details below.
Dataset Creation
-
We select a set of real-world static 3D scans of humans, wearing diverse clothing, from the data.
-
A professional clothing designer creates the clothing designs given rendered images of the scans, such that the designed 3D clothing faithfully reflects the observations in the image.
-
For each scan, we obtain the estimated SMPL-X body (provided by the ) that accurately fits the subject's body shape.
-
Each designed clothing is then draped on its corresponding SMPL-X body, and animated with a consistent set of 20 motion sequences of the subject 00096 from the CAPE dataset.
-
The simulated results are manually inspected to remove problematic frames, split into train and test splits (see below) and packed into the format required by the POP/SCALE codes.
- To get the point clouds from the simulated clothed body meshes, we first render 24 depth images of the simulated meshes using orthogonal projection with a pitch angle at -10, 0, and 15 degrees and with yaw angles for every 45 degrees. Then we fuse these depth images into a single point cloud and remove points that are too close to each other (<2e-3 meter).
Naming Conventions
Each packed data instance is named as <outfit_name>.<motion_sequence_name>.<frame_id>.npz
-
outfit_nameis the scan name in RenderPeople (RP for short below) and follows the its naming convention, e.g.rp_aaron_posed_002andrp_alexandra_posed_006. -
motion_sequence_nameis the name of the motion sequence taken from the CAPE dataset. For example,96_longshort_tilt_twist_leftis the motion sequencetilt_twist_leftperformed by subject00096when they wears thelongshortoutfit. Note: we only use the pose parameters from these CAPE sequences for the simulation; the96_longshorthere is just for identifying the original motion sequence in the CAPE dataset and is irrelevant from the subject/outfit in the ReSynth data. -
frame_idis the index of each frame in the motion sequence.
File Structures
We provide both packed data (directly compatible with the POP/SCALE code base) and the high-resolution point clouds for each frame.
The packed data are stored in train and test split folders. The original point cloud data are organized by the motion sequence names.
The folder structure are as follows:
├── packed/
│ ├── <oufit_name1>/
│ │ ├── train/
│ │ │ ├── <outfit_name1>.<motion_sequence_name>.<frame_id>.npz
│ │ │ └── ...
│ │ └── test/
│ │ ├── <outfit_name1>.<motion_sequence_name>.<frame_id>.npz
│ │ └── ...
│ ├── <oufit_name2>/
| └──...
└── scans/
├── <oufit_name1>/
│ ├── <motion_sequence_name1>/
│ │ ├── <frame_id>_pcl.ply
│ │ └── ...
│ ├── <motion_sequence_name2>/
│ └── ...
├── <oufit_name2>/
└──...
What's in the Packed Data
Loading a packed .npz file result in the following fields:
-
body_verts: the vertices of the SMPL-X body, posed according to the pose parameters of the current frame. -
scan_name: name of the current frame, as detailed in the "naming conventions" section above. -
scan_pc: a numpy array of shape (40000, 3), coordinates of a point cloud subsampled from the high-res point cloud, used as GT for training. -
scan_n: a numpy array of shape (40000, 3), the points' normals of the point cloud -
vtransf: a numpy array of shape (N_vert, 3, 3): the local-to-global transformation matrix of each vertex on the posed SMPL-X body. -
posmap32: the positional map, with a resolution of 32x32, of the posed body with each subject's own body shapes. It's used in the SCALE model to provide the body pose information and to query the shape decoder MLP. The valid pixels in it also serve as a basis point set where the predicted clothing offsets are added. -
posmap_canonical128: the positional map, with a resolution of 128x128, of the posed body with a "canonical body shape", i.e. the mean body shape of SMPL-X. It's used as the input to the POP model that provides body pose information. -
posmap256: the positional map, with a resolution of 256x256, of the posed body with each subject's own body shapes. It's used in the POP model to query the shape decoder MLP. The valid pixels in it also serve as a basis point set where the predicted clothing offsets are added.
In addition, we provide the SMPL-X body shape parameters of all subjects in the Download section too.
Train / Test Splits
We organize the 20 motion sequences into training and testing splits. The SMPL-X pose parameters of all frames are available for downloads. The test splits are chosen to include the following two test scenarios:
-
Interpolation: several motion sequences in the CAPE dataset are recorded multiple times where the subject wears different outfits. For example, in
rp_aaron_posed_002.96_longshort_squatsandrp_aaron_posed_002.96_jerseyshort_squats, although having the same motion definition ("squats"), they hardly contain identical pose parameters in both sequences as the subject cannot reproduce the exact same poses in different recordings. We see this as a good interpolation test, train the model on one of them and test on the other. -
Extrapolation: The motion sequence, or similar, has not been seen during training, for example the sequence
96_jerseyshort_hips.